
Comp 150, Peter Dordal, April 2006 Minor updates by Andy Harrington, April 15, 2007.
We will be using network process animations on the Net-SEAL web site. If you want to play along in class, you need to get yourself a login ID. It takes about two minutes. Go to http://www.net-seal.net/animations.php?aid=17, and fill out the new account screen and log in. Once logged in you can run the animations. The following links are also interspersed in the discussion below :
ARP Address resolution: http://www.net-seal.net/animations.php?aid=17
Switch congestion: http://www.net-seal.net/animations.php?aid=22
TCP Connections: http://www.net-seal.net/animations.php?aid=27
Buffering and Sequencing: http://www.net-seal.net/animations.php?aid=25
First an overview of the four network protocol layers most important to understand the Internet. They are each discussed in more detail below. The simplest network is the LAN (“Local-Area Network”). LANs are the "physical" networks that provide the connection between machines within, say, a school or corporation, often connected by Ethernet cables (discussed below) to directly link machines. With direct connection, communication is largely handled by the "link" layer of network protocols. LANs are, as the name says, "local", and so in connect multiple LANs into the Internet, a further protocol layer is used as an abstraction, the IP, or "Internet protocol" layer. Finally, TCP deals with transport and connections and actually sending data so it is received accurately. These three topics are often called "layers"; they constitute the "link layer", the "internetwork layer", and the "transport layer" respectively. Together with the "application layer" (the software you use), these form the "four-layer model" for networks.
The most common type of LAN is Ethernet, due to cost more than anything else. The original Ethernet had a bandwidth of 10 Mbps (megabits per second), though nowadays most Ethernet operates at 100 Mbps and gigabit (1000 Mbps) Ethernet is widely used in server rooms. Wireless LANs are gaining popularity, and may soon supplant wired Ethernet.
Data is transmitted in chunks called packets. Ethernet LANs can be unswitched, where every packet is received by every host and it’s up to the network card in each host to determine if the arriving packet is addressed to that host, or switched, in which intermediate nodes called switches make sure that each packet is delivered only to the host to which it is addressed. Unswitched Ethernet poses a security threat, and “password sniffers” that surreptitiously collected passwords used to be common. A better solution to the eavesdropping problem, however, is regular use of encryption.
On an Ethernet, addresses are six bytes long. Each computer has an Ethernet card. The address (MAC address) is burned into each Ethernet card at the time of manufacture; all are (supposedly) unique. The first three bytes determines the manufacturer; the subsequent three bytes are a serial number assigned by that manufacturer. Because addresses are assigned by the hardware, knowing an address doesn’t provide any direct indication of where that address is located on the network. In switched Ethernet, the routers must have a record of every Ethernet address on the network; this becomes unwieldy for large networks. Consider the analogous situation with postal addresses: Ethernet is somewhat like attempting to deliver mail using everyone’s social-security number as address, and providing each postal worker with a large catalog listing each person’s SSN together with their physical location. In contrast, real mail is addressed “hierarchically” using ever-more-precise specifiers: state, city, zip code, street address, and name / room#. Ethernet, in other words, does not scale well to large sizes. On the other hand, an advantage of having addresses in hardware is that hosts automatically know their own addresses on startup.
There is also a designated broadcast address. A host sending to the broadcast address has its packet received by everyone. This allows a host to contact another host when its hardware address is as yet unknown; typical broadcast queries have forms such as “Will the designated server please answer” or “Will the host with the given IP address please answer”.
See ARP Address resolution: http://www.net-seal.net/animations.php?aid=17 , Routing: http://www.net-seal.net/animations.php?aid=23.
Switched Ethernet works quite well, though, up to 10,000-100,000 nodes. Tables of that size are straightforward to manage. Typically a host is entered into the table when it first transmits: a switch notes the packet’s source address and path into the switch, and assumes that the same path is to be used to deliver other packets to that sender. If a host’s address hasn’t been seen yet, Ethernet still has a backup delivery option of broadcast to everyone (like on unswitched Ethernet) and allowing the host Ethernet cards to sort it out. Since this is not generally used for more than one packet (after that, the switches will have learned the correct routing-table entries), security is pretty much a non-issue.
The <host,destination> routing table is often easier to think of as <host,next_hop>. In other words, to route a packet a server does not need to know the entire path to the final destination, it only needs to know the next server along the way to send it to, as when a US mail vehicle delivers mail from one city to another, it does not carry the information to find every street address in the destination city. The destination city's local post offices handle that.
A buffer is a temporary storage places for a block of data. Packets are modest-sized buffers of data that are individually transmitted across a network. Ethernet (discussed below) allows a maximum of 1500 bytes of data; typical TCP/IP packets (discussed below) often hold only 512 bytes of data. While there are proponents of larger packet sizes, larger even than 64KB, it should be noted that the ATM (Asynchronous Transfer Mode -- used for an interactive terminal like PuTTY) model uses 48 bytes of data per packet. In front of the data is a header (or more likely a series of headers). The header will contain the address of the destination. Internal nodes of the network called routers or switches will then make sure that the packet is delivered to the requested destination.
One significant advantage of packets is that the same link can carry, at different times, traffic to different destinations and from different senders. Thus, packets are the key to supporting shared transmission lines. The alternative of a separate line between every pair of machines grows prohibitively complex very quickly.
When a router/switch receives a packet, it (generally) reads in the entire packet before looking at the header to decide to what next node to forward it. This is known as a store-and-forward process, and introduces a delay equal to the time needed to read in the entire packet. For individual packets this forwarding delay can’t be avoided, but if one is sending a long train of packets then by keeping multiple packets en route at the same time one can greatly reduce the significance of the forwarding delay.
Total packet delay is due to the following features: (ms is short for millisecond: 1/1000 of a second)
Bandwidth delay, is to send 1000 Bytes at 20 B/millisecond will take 50 ms.
Propagation delay due to the speed of light; if you start sending a packet right now on a cable across the US, the first bit won’t arrive at the destination until about 20 ms later. The bandwidth delay then determines how much after that the entire packet will take to arrive.
Store-and-forward delay, equal to the sum of the times each router takes to receive a packet. These times in turn depend on the respective link bandwidths.
Queuing delay, or waiting in line at busy routers. At bad moments this can exceed 1 sec, though generally is less than 100 ms.
See Switch congestion: http://www.net-seal.net/animations.php?aid=22
To solve the scaling problem with Ethernet, and to allow support for other types of LANs and point-to-point links as well, the Internet Protocol was developed. In the early days, IP networks were considered to be “internetworks” of basic networks (LANs); nowadays users generally ignore LANs and think of the Internet as one large (virtual) network. Perhaps the central issue in the design of IP was to support universal connectivity (everyone can connect to everyone else) in such a way as to allow scaling to enormous size (currently ~108 nodes, although IP should work to 109-1010 nodes), without resulting in unmanageably large routing tables (currently none are larger than 105 nodes, and that seems to be a practical maximum.)
To support universal connectivity, IP provides a global mechanism for addressing and routing, so that packets can actually be delivered from any host to any other host. IP addresses are 4 bytes (32 bits), and are part of the IP header that generally follows the Ethernet header. The Ethernet header only stays with a packet for one hop; the IP header stays with the packet for its entire journey across the Internet. An essential feature of IP addresses is that they consist of a "network" part and a "host" part. The"legacy" mechanism for network/host allocation was to divide according to ranges by the first byte:
|
First Byte |
Network Bits |
Host Bits |
Name |
Feature |
|
0-127 |
8 |
24 |
Class A |
Few networks, but very very large |
|
128-191 |
16 |
16 |
Class B |
Loyola has (or had) one, net=147.126 |
|
192-223 |
24 |
8 |
Class C |
Millions of networks, but each one is small |
Nowadays the division into network & host is dynamic, and can be made at different positions in the address at different levels of the network.
All hosts with the same network part of the address (same network bits) must be located together (on the same LAN!), and so outside of that site only the network bits are needed to route a packet to the site. The entire point of this network/host separation is that routers list only the network parts of the destination addresses, which saves space. There are currently around 100 million hosts on the Internet, but only 100,000 or so networks. A routing table of 100,000 entries is (just barely) feasible; a table a hundred times larger is not, let alone a thousand times larger. You can think of the network bits as analogous to the “zip code” on postal mail, and the host bits as analogous to the rest of the address. Alternatively, one can think of the network bits as like the area code, and the host bits as like the rest of the phone number. Newer protocols that support different net/host division points at different places in the network allow support for addressing schemes that correspond to, say, zip/street/user, or area code/exchange/subscriber#.
In addition to routing and addressing, IP must also support the transmission of packets that may be too large for some intermediate physical LAN. For example, one form of LAN is a token ring. Two token rings with a 4K max packet size can send and receive packets of size 4KB, but if they are connected by an intervening Ethernet that can only forward packets of size 1.5KB, something has to give. IP handles this by supporting fragmentation. The IP approach is awkward and inefficient, and IP fragmentation is seldom used (instead, IP tends to choose rather small packet sizes (eg. 512 bytes) to avoid it).. However, fragmentation is essential conceptually,in order for IP to be able to support large packets without knowing anything about the intervening networks.
Note that IP is a "best effort" system; there are no acknowledgements or retransmissions or any of that stuff. We ship it off, and hope it gets there. Most of the time, it does.
Now let's look at a simple example of how IP routing works. Machines can be thought of as either hosts (user machines, with a single network connection) or routers (these do packet-forwarding only, and are not directly visible to users, and essentially always have at least two different network interfaces representing different networks that the router is connecting). (Machines can be both hosts and routers, but this is tricky.) /
Let's start with the sending host S, delivering to a destination host D. The IP header of the packet contains D's IP address (and, for that matter, S's address). First of all, S must determine whether D is on the same LAN as the sender or not. This is done by looking at the network part of the destination address, which we'll denote by Dnet. If this net address is the same as S's (that is, is equal numerically to Snet), then S figures D is on the same LAN as itself, and can do direct delivery. It looks up (never mind how) the appropriate LAN address for D, attaches a LAN header to the packet in front of the IP header, and sends the packet straight to D via the LAN.
If, however, Snet and Dnet don't match, then S looks up a router to use. Most ordinary hosts have only a single router to which they connect, making this choice very simple. If you are a dial-up, DSL, or cable-modem user, your router is at the other end of your connection. S then forwards the packet to the router, again using direct delivery over the LAN. Note that the IP destination address in the packet remains D in this case, although the LAN destination address will be that of the router.
The router strips off any LAN address from the incoming packet, but leaves the IP address. It extracts the destination D, and then looks at Dnet. The router first checks to see if it is on the same LAN as D; recall that the router connects to at least one additional network besides the one for S. If the answer is yes, then the router does direct delivery to the destination, as above. If, on the other hand, Dnet is not one to which the router is connected directly, then the router consults its internal routing table consisting of a list of networks each with an associated next-hop address. These <net, next_hop> tables compare with switched-Ethernet’s <host,next_hop> tables; the former type will be smaller because there are many fewer nets than hosts. Next-hop addresses are chosen so that the router can always reach them via direct LAN delivery; generally they are other routers. The router looks up Dnet in the table (generally there is a catchall default entry, so the table doesn't have to be huge), and uses direct LAN delivery to get the packet to the corresponding next-hop machine. The packet's IP header remains essentially unchanged, although the router most likely attaches an entirely new LAN header.
The packet continues being forwarded like this, from router to router, until it finally arrives at a router that is connected to Dnet; it is then delivered directly to D.
Just how routers build their <destnet,next-hop> tables is a major topic itself. Small sites have their routers just exchange information with their immediately neighboring routers; tables are built up this way through a sequence of such periodic exchanges. Larger sites (such as large ISPs) add a protocol in which routers propagate information about the state of each link; all routers receive all this information and each one builds and maintains a map of the entire network. The routing table is then constructed (sometimes on demand) from this map. Unrelated organizations exchange information through the Border Gateway Protocol, which allows for a fusion of technical information (which sites are reachable at all, and through where) with “policy” information representing legal or commercial agreements: which outside routers are “preferred”, whose traffic we will carry even if it isn’t to one of our customers, etc.
Before Internet 2, Loyola’s largest router table consisted of maybe a dozen internal routes, plus one “default” route to the outside Internet. Internet 2 is a consortium of research sites with very-high-bandwidth internal interconnections that don’t also carry commercial traffic.
You can do a variety of thing in Windows to check on networking at a low level.
First open a command line window with Start Menu -> run and enter cmd.
To find your computer's 4-byte IP
address enter the command
ipconfig
To translate a URL name into a
4-byte IP address, enter a command like these
nslookup
google.com
nslookup
flickr.com
To check the timing of IP requests
enter commands like
ping
google.com
To trace the path and timing to a
destination enter a command like
tracert
google.com
Looking ahead to TCP, enter the netstat command (one word) to see all the active TCP connections on your computer.
TCP stands for Transmission Control Program, and it serves as a "transport" layer for application data. IP packets are sent from one host to another, but the routing is a "best-effort" mechanism, which means packets can and do get lost sometimes. Data that does arrive can arrive out of order. The sending application has to keep track of division into packets; that is, buffering. Finally, IP only supports sending to a specific host; normally, one wants to send to a given application running on that host. Email and web traffic, or two different peoples' web sessions, should not be commingled!
TCP extends IP with the following services:
reliability: TCP numbers each packet, and keeps track of which are lost and retransmits them after a timeout, and holds early-arriving out-of-order packets for delivery at the correct time. Every arriving data packet is acknowledged by the receiver; timeout and retransmission occurs when an acknowledgement isn’t received by the sender within a given time.
connection-oriented: Once a TCP "connection" is made, data sent over that connection needs no further addressing.
stream-oriented: The application can write 1 byte at a time, or 100KB at a time; TCP will buffer and/or divide up the data into appropriate sized packets.
port numbers are used to specify the receiving application for the data, and also to identify the sender.
See TCP Connections: http://www.net-seal.net/animations.php?aid=27 , Buffering and Sequencing: http://www.net-seal.net/animations.php?aid=25
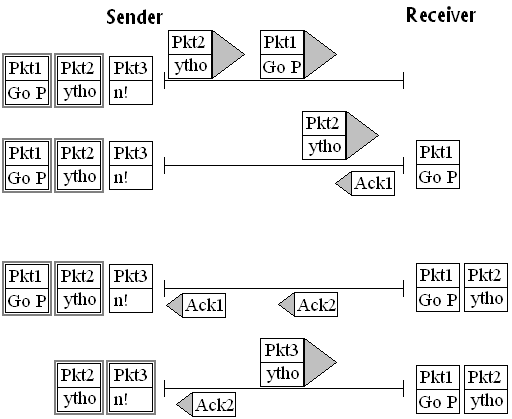
Simplify the transmission path and consider only the Sender and Receiver. Illustrations follow with oversimplified graphics and impractically small data packets for simplicity. The diagrams below correspond roughly to the fancier animations for TCP Connections and Buffering and Sequencing. Suppose the data "Go Python" is to be sent and suppose each packet can only handle 4 characters of data. the initial Data becomes three packets:
The packets are numbered in order. Hence if everything works flawlessly the first time, the sequence could be like the following. The lines progress in time. On the Sender side, packets sent are indicated with a gray rectangle. Packets not yet sent have no such marking. Packets transmitted to the receiver are show on the right. Besides data packets there are also control packets. One kind is an acknowledgment of the receipt of a data packet. It indicates the sequence number of the data packet successfully received. These packets go from the data receiver back to the sender. The sender notes what packets have been successfully transmitted to the other end. In the diagram, those packets are removed from the waiting packets on the sender's side.

This diagram above shows flawless transmission. In fact the
Internet is noisy and routers fail. It is possibility is
that a packet gets totally lost. Still TCP can recover by
resending the packet if it takes too long for an acknowledgement:
Acknowledgements also pass over the Internet, so they, too, can be lost. In this case a packet is resent when it is not actually needed, but no harm is done:

What is worse that a packet being lost?
Since the transmission is noisy, data can be corrupted.
For instance, instead of communicating that a check is drawn on
your account for $105, it could come back as $905. Packets
include extra information that catches the existence of most data
corruption. If the receiver receives a packet that it detects
as corrupted, it returns a negative acknowledgment to the sender,
with the sequence number (assuming that part is intelligible). The
diagram uses Nak as abbreviation for negative acknowledgment. This
allows the sender to resend the data faster than just waiting until a
packet is decided to be lost.
The diagrams above have concentrated on a single packet at a time, but in fact the most efficient procedure through a path including many routers is to have multiple packets in transit at once. A simple, completely orderly example is:
Different packets may go by different routes and arrive at different times. The receive must keep the packets in order via their sequence numbers, not the temporal order of arrival.

When you enter a site name in a web browser, it starts up by opening a TCP connection to that site; the connection is made to the server’s port 80 (the standard web-traffic port). TCP is ubiquitous, although the real-time performance of TCP is not predictable and so sound/video types of applications tend to use something different.
Sliding-windows is used to keep multiple packets en route at any one time. This minimizes the effect of store-and-forward delays, and propagation delays, as they then only count once for the entire packet stream and not once per packet. The window size represents the number of packets en route at any one time; if the window size is 20, for example, then at any one time 20 packets are out there (probably 10 data packets and 10 returning acknowledgements). As each acknowledgement arrives, the window “slides forward” and the data packet 10 packets ahead is sent. For example, consider the moment when packets 20-29 are in transit. When Ack20 (acknowledgement 20) is received, Pkt30 is sent, and so now 21-30 are in transit. When Ack21 is received, Pkt31 is sent, so 22-31 are in transit.
The ideal window size is such that it takes one round-trip time to send an entire window, so that the next Ack will always be arriving just as the sender has finished the window. Determining this ideal size, however, is difficult; for one thing, the ideal size varies with network load. As a result, TCP approximates the ideal size. The window size is slowly raised until packet loss occurs, which TCP takes as a sign of network congestion. At that point the window size is reduced to half its previous value, and the slow climb resumes. The effect is a “sawtooth” graph of window size with time, which oscillates (more or less) around the “optimal” window size.
A busy server may have thousands of connections to its port 80 (the web port) and hundreds of connections to port 25 (the email port). Web and email traffic are kept separate by virtue of the different ports used. All those clients, though, are kept separate because each comes from a unique <host,port> pair. A TCP connection is determined by the <host,port> pair at each end; traffic on different connections does not intermingle. That is, there may be multiple independent connections to <www.luc.edu,80>. This is sort of analogous to certain 800 phone numbers, where there can be multiple callers at the same time to the same 800 number. Each call is answered by a different operator (corresponding to a different CPU process), and different calls do not “overhear” each other.
TCP’s automatic acknowledgement system means that data that has to be retransmitted has its delivery delayed until that retransmission succeeds; furthermore, the following data is also delayed. While this works just fine for large file transfers, it doesn’t work quite as well for voice and video. In these forms, timeliness is more important than completeness. A few lost packets mean some voice dropouts (pretty common on cell phones) or flicker/snow on the video screen; both of these are better than stalling out completely. So, as the Internet moves towards more voice (such as Voice over IP, or VOIP, a form of phone service) and video, non-TCP transport mechanisms are an active research agenda.
A funny and informative 10 minute animated web video on the
transmission of information over the Internet is at
http://www.warriorsofthe.net/movie.html
(Choose
your language of choice -- it has been translated many times.)
it is very definitely not professor-like, more YouTube-like. It
might make some stuff stick in your head in a way these web notes
never could.
One problem with having a program on your machine listening on an open TCP port is that bad guys may connect and, using some known flaw in the software on your end, do something bad to your machine. Damage can range from the unintended downloading of personal data to compromise and takeover of your entire machine, making it a distributor of viruses and worms or a steppingstone in later break-ins of other machines. An attack known as buffer overflow, where some internal memory location fills with network-supplied data and overflows, overwriting parts of the program itself (that are later executed), is the most common (and most serious, when it works) form of total-compromise attacks.
A firewall is a program to block such outside connections. Generally ordinary workstations don’t ever need to accept connections from the Internet; client machines instead initiate connections to better-protected servers. So blocking incoming connections works pretty well; when necessary (eg. for games) certain ports can be selectively unblocked.
The original firewalls were routers. Incoming traffic to certain ports was blocked for servers; for non-servers, often all inbound connections were blocked. This allowed unprotected machines to operate reasonably safely; however, it also meant that client machines could not accept connections no matter what. Nowadays per-machine firewalls are common: you can configure your machine not to accept inbound connections to most (or all) ports regardless of whether software on your machine requests such a connection.
Another way of protecting ordinary machines is Network Address Translation, or NAT. This also conserves IP addresses. Instead of assigning each host a “real” IP address, instead just one address is assigned to a border router. Internal machines get “internal” IP addresses, typically of the form 10.x.y.z (addresses beginning with 10 can’t be used on the Internet). Inbound connections to the hidden machines are banned, as with firewalls. When a hidden machine wants to connect to the outside, the NAT router intercepts the connection, allocates a new port, and makes the connection itself using that new port and its own IP address. The remote machine responds, and the NAT box remembers the connection and forwards data to the correct hidden host. Done properly, NAT improves the security of a site. It also allows multiple machines to share a single IP address, and so is popular with home users who have a single broadband connection but who wish to use multiple computers.