Algorithms Assignments, Spring 2019
General Assignment Information
- Numbered problems are in the class text unless otherwise mentioned. For instance, "2.1: 3, 9" refers to the section 2.1, exercises 3 and 9. Sometimes I will give a parenthetical comment after a problem number, either clarifying it or slightly modifying it
- I put 2nd edition numbers in square braces: 11[10] means problem 11 in 3rd edition, with a reminder that it is 10 in the second edition. Similarly with Section numbers: 5.1[4.1] means section 5.1 in 3rd edition, 4.1 in second edition.
- There are hints at the back of the book.
- Everyone should work on all the problems in the regular homework. It is much less helpful for learning to only look at completed solutions that others come up with. Days ahead I will post what groups are to be original solvers and first reviewers for each problem.
- Under no circumstances should old official solutions from the text or me be consulted or posted.
- This gives most of the likely problems, though there may be timing shifts, particularly some moving to earlier of later assignements. The placement of the problems for an assignment is final when that homework asignment is posted in Piazza.
HW1
- 2.1: 9 (explain)
- 2.2: 2, 3 (Using algebra and our rules is generally a lot shorter than calculus),
- 2.2: 5, 7d (big challenge without the hint; not so bad with the hint),
- 2.2: 10 (not in 2nd edition) all and a part e: balanced binary search tree
- 2.2: 11 (not in 2nd edition) O(1) weighings. Clearly state the algorithm!
- 2.2: 12 [10] (meaning number 10 in 2nd edition)
- 2.3: 4ade (based on time asymptotic order),
- 2.3: 6ade (also based on time asymptotic order)
HW2
- 2.4: 1abc (solve exactly),
- 2.4: 11[10] (explain)
- 3.1: 4
- 3.4: 2 (You can just specify that you generate combinatorial objects needed, as in the Knapsack problem pseudo-code in class. You do not need to detail how. The definition of Hamiltonian Circuit is in problem 1.3:5, p. 24[25])
Problems based on Appendix B or 04A_Recurrence.html: Find the Θ order of T. Assume integer division in the recurrence relation. Recall logb bk = k.
- B1. T(n) = 3 T(n/3) + 2
- B2. T(n) = 4 T(n/2) + 5n2
- B3. T(n) = 9T(n/3) + n5 + 100n
- B4. T(n) = T(n/3) + n2
- B5. T(n) = T(3n/5) + n5
HW3
- 5.1[4.1]: 1,
- 5.1: 7 (definition of stable sort on p. 19[20]),
- 5.1: 11
- 5.2[4.2]: 3
- 5.2: 8
- 5.2: 11
- 4.4: 5
- 5.3: 8 (Give this an early read - requires thought.)
- 5.4: 9
Also these problems not in the book:
Problem A: Suppose my non recursive quicksort algorithm is used, that minimizes stack height. Suppose the tree below shows the size of the lists partitioned from each larger list (assuming quicksort is used all the way down to the lists of size 2). The real stack would need to show both starting indices and length at each step, but the order of processing only depends on the lengths, so I just show lengths and omit the starting indices:
33 / \ 6 26 / \ / \ 3 2 1 24 / \ \ / \ 1 1 1 12 11 / \ / \ 8 3 5 5 / \ / \ / \ / \ 4 3 1 1 2 2 2 2 / \ / \ / / \ \ 2 1 1 1 1 1 1 1 \ 1Only lengths greater than 1 go on the stack, and when a list is split into two parts that do go on the stack, the smaller goes to the top of the stack.
I show the states at the beginning of the first few times through the main loop, one per line (with only sizes), placing the top of the stack at the left:
33 6 26 2 3 26 3 26
In the same format show the whole sequence of stacks and mark the line showing the longest stack, appending " <<<" to that line.
Problem B: My Java quicksort algorithm has inner loops:
while (data[iHi] > pivot) iHi--; while (data[iLo] < pivot) iLo++;
These loops will both stop at a pivot value, and you could end up swapping two elements that are equal to the pivot. This seems wasteful. An alternative is to include the pivot in only one of the categories (say consider it a large element), and make one of the inequalities not strict:
while (data[iHi] >= pivot) iHi--; while (data[iLo] < pivot) iLo++;You need one more small change to avoid an infinite loop: As the book discusses, you need to place a sentinel at the beginning of the array, a value smaller than anything in the array (like the minimum possible integer value), and have your actual data start at index 1.
Analyse the running time of these two versions if all the data is equal (bigger than the artificial sentinel value).
Problem C: The square of a matrix A is its product with itself, AA.
Show that five multiplications are sufficient to compute the square of a 2 × 2 matrix of integers.
What is wrong with the following algorithm for computing the square of an n × n matrix?
“Use a divide-and-conquer approach as in Strassen’s algorithm, except that instead of getting 7 subproblems of size n/2, we now get 5 subproblems of size n/2 thanks to part (a). Using the same analysis as in Strassen’s algorithm, we can conclude that the algorithm runs in time O(nlg 5).” You are likely to want my Hint.
Problem D: Modify Mergesort.java or mergesort.py so mergesort returns the number of inversions in the original list, and does not increase the asymptotic order of the function, as discussed in class. Modify the testing code to show off the new version. This version in mergesort.py is verbose, but quite standard, and fairly easy to modify.
Problem E: What would be a good sort to use? Explain
- Many large array sorts to do, with an overall interest in throughput.
- Large array of data, sensitive to maximum time in a sort, but having extra space.
- Large array of data, sensitive to maximum time in a sort, and also having space limitations.
- Many small array datasets, many already in order.
- Large linked list often close to being in order.
HW4
- 6.1: 4[6]
- 6.4: 1 (a is my algorithm, b is inserting each new element at end and letting it bubble up, also do c),
- 6.4: 3 (count height so a single root node is considered height 0),
- 6.4: 8[7] (prove yes or give counter example)
- Amortizing-1 and Amortizing-2 from end of Amortizing Notes
HW5
- Problem G: For n = 4, 5, what are the precise lower bounds for the number of comparisons from the decision tree analysis of a comparison based sort? For which does the exact worst case for mergesort match this bound? You can get the exact mergesort numbers from a recurrence relation for the number of comparisons, and explicitly calculate up to n=5.
- Problem H: Find a lower bound on the number of comparisons needed to merge sorted lists of length k, m. Let n = k+m. You will need to use this fact: the number of sequences of k a's and m b's is n!/(k!m!), the number of combinations of k out of n items. Your answer should be exact, but it may involve summation formulas. This is a direct application of the decision tree idea. How does the fact I give help you? Explain why your answer is true.
- 7.3: 1, 2, 3, 6b, 7 (addition in the 3rd edition)
- Problem I: The table of average number of comparisons for different
hashing methods is actually comparing apples and oranges - not a good
comparison. Longer arrays are an issue because they take up more memory.
Linked lists also take up memory, however, and the tables only compare
data for equal array lengths, not equal total amounts of memory
consumed. Remember that in the open addressing models, the array
elements are the size of a data item, since they are stored there. In
separate chained hashing the array only contains a link, and each item
in a linked list requires another link. (The situation in part a applies
when all objects are referred to by pointers to the heap, like in Python
or if the items are Objects in Java. The situation in part b applies
where you have a larger primitive piece of data in Java or C++, or if
you have an object stored in place in C++, or a struct in C or C#.)
- Suppose the data being stored takes up 1 unit of memory per item, and a link also takes up 1 unit of memory. Compare the average number of comparisons for chained hashing with a load factor of alpha with the number of comparisons for open addressing (linear and double hashing) with the same amount of memory consumed and the same amount of data stored, not the same array size. In your table, include chained load factors of .25, .5, .75, 1, 1.5, and 2. You are strongly encouraged to code functions to do this, and generate the final results automatically. By hand would be tedious and error prone. Use the formulas from the notes - or adapt hashAvgComp.py. The central new calculation is to figure out the load factor for open hashing that would use the same amount of memory as for chained hashing with load factor alpha. Hint: It may be easier to figure out the formula if you assume a particular array size for the chained hashing table, but that number should cancel out in the final answer for the open load factor.
- The only change from part a is that each data item take up 4 units of memory (like with long doubles in C or C++, or an object stored in place).
- Exercises in my notes on hash tables and B-trees: 1-6
HW6
- 3.5[5.2]: 1,
- 3.5[5.2]: 2,
- 3.5[5.2]: 3 (For an undirected graph. Also explain or give a counter-example),
- 3.5[5.2]: 4,
- 3.5[5.2]: 6
- 4.2[5.3]: 1,
- 4.2[5.3]: 5,
- 4.2[5.3]: 7,
- 4.2[5.3]: 9ac
- Problem J Carefully work out the algorithm to produce the adjacency list for a reversed graph given the adjacency list for an original graph, in time O(|E| + |V|). You can use pseudo code, Java, the procedural Python setup of mine or the OO Python setup of mine. (My solution fits in my OO version.)
HW7
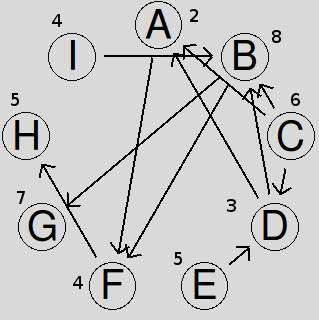
- Problem K: The task dependency graph shows the time needed to complete each node. What is the minimum time to complete all tasks? What is the critical path?
- 9.1: 3,
- 9.1: 4 (new),
- 9.1: 9a[7],
- 9.1: 10[8],
- 9.1: 13[9]
- 9.2: 1b,
- 9.2: 2ab (explain or give a counter-example),
- 9.2: 4 (explain or give a counter-example)
- 9.3: 1bc,
- 9.3: 2b,
- 9.3: 3,
- 9.3: 9
HW8
9.4: 1
9.4: 4 (Explain clearly)
9.4: 10
Problem L: Party problem. You know who knows who among n people that you would like to have come to a party. Suppose you number the prople 0 ... (n-1), and have a symmetric nxn boolean matrix Knows of who-knows-who, Knows[i][j] is true if person number i knows person number j. It is symmetric because we assume "knows" is symmetric: If I know you, you know me. You make further requirements that you want each person to have at least 5 new people to meet at the party, and also, so nobody feels too isolated, each person should already know at least 5 people at the party. Your original list may not satisfy these extra two conditions, so you may need to eliminate some people from the invitation list (or maybe you cannot have a party at all with these restrictions). Clearly state an algorithm to find a largest possible subset of the n people that you could invite and satisfy the the other two requirements. For the basic problem, you may find an O(n^3) algorithm and explain its order and its logic. O(n^2) without using hash tables would be even better, but not required! Be careful of your time bound calculations in dealing with collections.
Hint for L: If a person would not satisfy the extra conditions for a list that you are currently considering, could that person satisfy the conditions for any reduced list?
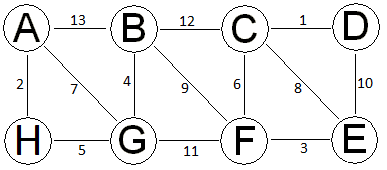
Problem M: As in class, follow Kruskal's algorithm for the graph above, keeping track of the union-find data structure to support it. Note that the union-find in-tree data structure you are asked to keep track of is totally separate from the MST itself. When edges have equal weight, consider them in alphabetical order. Have a step for each edge being considered, and update the in-trees for the two compression-finds and the union (when a union happens). Label each step with the edge being considered. Put a * beside the edge if it gets considered, but not included in the MST. Keep track of the rank for each root vertex. Remember the only rank that can change is the rank for a root of a new union. In doing unions, if the two parts have equal rank, make the vertex EARLIER in the alphabet be the root. This is important for the full illustration of options as well as for checking against my answers. Also note that while edges that would make cycles do not affect the MST, the finds required to discover that they are in the same component can cause compression, so the in-tree data structure can change even for an edge that is only considered for the MST but not added to the MST. You only need to draw the final MST graph, just once at the end of your steps. At the intermediate steps, just list the edge you are considering.
Problem N: Consider a possible divide-and-conquer approach to minimal spanning trees: Suppose the vertices of the connected weighted graph G are partitioned into nonempty disjoint sets V1 and V2 such that the weighted graphs G1 and G2 restricting G to V1 and V2 respectively are each connected. Suppose we find minimal spanning trees T1 for G1 and T2 for G2. Finally, find a minimal weight edge vw from V1 to V2. Let T be T1 + T2 + vw.
- Must T be a spanning tree for G? Explain or give a counter-example.
- Must T be an MST for G? Explain or give a counter-example.
Problem P: See the MST Edge Swapping Theorem added to the notes and the Lemma right after it. Prove the Lemma.
Hint for P: First, since the number of edges in an MST for any one component of a graph must be one less than the number of vertices in the component, the number of edges in T not in S is also k. Let vw be the edge of lowest weight in either S or T that is not in the other. Because of the symmetry of the descriptions, we can assume this lowest weight edge is in S.... See the proof of the MST Cut Theorem for inspiration if you need it.
DG4.8: Here is a proposed way to deal with negative weight edges in finding minimum distance paths from one vertex s:
- Find the most negative edge weight, -k
- Add k+1 to all edge weights, so they are all positive.
- Solve Dijkstra's algorithm with these new weights.
- Use the same paths (but not the same total distances, of course) to solve the original problem.
Does this always work? Give a proof or a counter-example.
HW9
8.4[8.2]: 1 (Just find the transitive closure matrix. You do not need to use Warshall - likely easiest drawing a picture, completing the transitive closure visually, and translating back to a graph.)
8.4[8.2]: 2b, 6
8.1: 7[9],
8.1: 12[10] (This problem has been simplified merely in the way it was stated. If P(i,j) had not already been defined, you would probably have first thought to quantify probabilities in terms of the number of games won so far, which is not useful.)
8.2[8.4]: 1a, 3
Problem Q (DasGupta): Suppose you are given text with spaces, capitalization, and punctuation removed, like 'whatintheworld'. You also have a dictionary, that in O(1) returns whether a sequence of letters forms a legal word. Give an algorithm to determine whether the text that you are given can be completely split into a sequence of legal words. For a sequence of n letters, your algorithm should be O(n2). (This is important for AI understanding speech, since words tend to run together. The actual problem is much more complicated, since you want to look for words that make sense together in context.) The subproblems should be pretty obvious. What data will you store in your table?
Problems R, S stated in the Dynamic Programming (Ch 8) notes. You can do it in clear, complete pseudocode, but given the Python codes, it may save you checking time to make it executable Python!
Problem T (DasGupta): I want to travel along a route with n motels at mileage m1 < m2 < ... < mn. I start at mile 0, will stay at a motel each night along my way, and end up at the last motel. Ideally I would travel 400 miles a day, but that may not be possible given the spacing of motels. In planning my itinerary, I assume a penalty measure of (400-d)2 if I travel a distance d in a day. I want to minimize the sum of penalties for each day's travel. For example if there are motels at mileage 300, 375, 600, 850, and 1210, I could stay at the motels at mileages 375, 850, and 1210, for a total penalty of
(400-(375-0))2 + (400-(850-375))2 + (400-(1210-850))2 = 252 + 752 + 402.
- Show that a greedy solution, where I always choose the next hotel to be the closest possible distance to 400, is not optimal in general (though it does happen to be best with the example mileage sequence I gave). The easiest way is to come up with a simple counter-example.
- Give a dynamic programming solution.
- Elaborate your solution so you also print the mileages of the sequence of motels that I stay at.
Hint: Use the most obvious subproblems. Similar, but simpler, than lineBreak.py.
Problem U: Longest common subsequence. Given two sequences,
a1, a2, a3, ..., an andb1, b2, b3..., bm,determine the length of the longest common subsequence. For instance in
7, 2, 5, 3, 4, 5, 1, 7 and1, 4, 2, 3, 7, 4, 1, 3, 9,the longest common subsequence has length 4. A maximal length subsequence is: 2, 3, 4, 1. Find an O(mn) solution. With the same comment as in problem R, take it one step further to produce a longest subsequence.
Hint: Use the suggested subproblem data from the notes for this situation. Palindrome was also trying to match two sequences....
HW10
11.3: 5
11.3: 6
11.3: 7a (Note that the assumption made in 7a is to reduce your work, but checking legality is required in general to confirm a solution),
11.3: - 9ac (Show polynomial reducibility in both directions for clique and independent set; you can skip the middle one)
11.3: 11[10]
11.3: 12a[11a]
Problem W
- A Hamiltonian Path is a path that visits each vertex once, but being a path rather than a cycle, it starts and ends at different vertices. Show that the undirected Hamiltonian path decision problem is polynomially reducible to the directed one.
- Based on your reduction from part a, and the knowledge that the directed problem in NP complete, could you conclude that the undirected problem is NP complete?
- Same question as b. with except with the italicized directed and undirected swapped.
W Hint: The mapping should be easy.